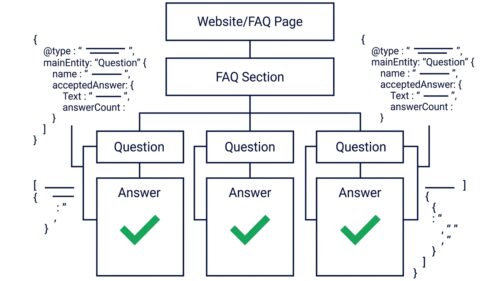
- Status 2026: Etabliertes Governance-Format für B2A-Strategien
- Rechtssicherheit: Unterstützt Compliance gemäß EU AI Act Art. 53
- Wirtschaftlichkeit: Minimale Umsetzungskosten bei hohem Schutzfaktor
- Kernfunktion: Kuratiertes Inhaltsverzeichnis gegen KI-Halluzinationen
Ein llms.txt Generator ermöglicht es Unternehmen, eine strukturierte Orientierungshilfe für KI-Crawler bereitzustellen, um die Korrektheit von Antworten in Systemen wie ChatGPT oder Perplexity aktiv zu beeinflussen. Anstatt die Kontrolle über die eigene Markendarstellung vollständig Algorithmen zu überlassen, definieren Sie über dieses Format präzise, welche Inhalte für Large Language Models relevant sind. Dies reduziert das Risiko von Halluzinationen und sichert die Informationsqualität im KI-gestützten Web.
- Was ist eine llms.txt-Datei für GPTBot, ClaudeBot und PerplexityBot wirklich?
- llms.txt vs. robots.txt: welche Funktion steuert Zugriff, welche Funktion steuert Orientierung?
- Welche 5 Pflicht-Sektionen eine llms.txt für Unternehmenstextgeneratoren und Wissensseiten enthalten sollte
- Wie Du eine llms.txt in 6 Schritten sauber aufsetzt, prüfst und veröffentlichst
- Welche Fehler bei AI-Bot-Allowlist, Schema-Markup und Over-Blocking die Sichtbarkeit am stärksten bremsen
- Welche Compliance-Fragen der EU AI Act und TDM-Opt-out für llms.txt in Deutschland auslösen
- Welcher Grundsatz für KMU gilt: llms.txt ist Governance, nicht Garantie
- Praktisches Fazit
Was ist eine llms.txt-Datei für GPTBot, ClaudeBot und PerplexityBot wirklich?
Eine llms.txt-Datei ist kein Ranking-Knopf, sondern ein Leitfaden für KI-Crawler wie GPTBot, ClaudeBot und PerplexityBot. Sie bestimmt, welche Inhalte Deiner Website diese Systeme beim Training oder bei Antworten nutzen dürfen, und welche nicht. Das Prinzip: Du listest URLs, Beschreibungen und optional Metadaten auf, damit die Crawler Deine Seiten gezielt erfassen. Die Realität ist weniger glamourös. Die Beachtung durch LLM-Crawler ist begrenzt und nicht standardisiert [Quelle: Limy AI, 2026].
Die echte Aufgabe von llms.txt heißt Governance, nicht Performance. Du steckst ab, welche Inhalte in KI-Antworten zitiert werden dürfen, Produktbeschreibungen, Whitepapers, FAQ, und schließt gleichzeitig Tabu-Zonen aus: interne Doku, rechtliche Hinweise, Kundendata. Das Kernproblem: Es gibt keinen verbindlichen Standard wie bei robots.txt. GPTBot, ClaudeBot und PerplexityBot interpretieren llms.txt unterschiedlich. Viele ignorieren sie komplett. Du bekommst also keine Garantie, dass Deine Vorgaben eingehalten werden.
Für KMU heißt das konkret: llms.txt ist ein sauberes Signal, aber kein Kontrollhebel. Du zeigst Transparenz, dokumentierst Deine Wünsche, ob der Crawler das umsetzt, bleibt offen. Wenn Du llms.txt aufbaust, wähle Inhalte mit echtem Mehrwert für KI-Systeme: strukturierte Daten, präzise Beschreibungen, aktuelle Fakten. Vage Formulierungen oder generische Seiten ohne Kontext? Raus damit. llms.txt beeinflusst nicht Dein Google-Ranking. Es bestimmt, ob ChatGPT oder Perplexity Deine Website in ihrer Antwort zitieren, oder ignorieren.
llms.txt vs. robots.txt: welche Funktion steuert Zugriff, welche Funktion steuert Orientierung?
Die Steuerung von KI-Bots und klassischen Suchmaschinen-Crawlern erfordert eine klare Trennung zwischen technischem Zugriffsschutz und inhaltlicher Führung. Während die robots.txt seit Jahrzehnten den Standard für die Zugriffskontrolle bildet, etabliert sich mit der llms.txt ein neuer Ansatz, der Large Language Models (LLMs) gezielte Kontextinformationen bereitstellt. Für Unternehmen im deutschen Mittelstand ist dieser Unterschied entscheidend, um einerseits das Urheberrecht gemäß § 44b UrhG zu wahren und andererseits die Sichtbarkeit in KI-gestützten Suchergebnissen (SGE) sicherzustellen.
| Merkmal | robots.txt | llms.txt |
|---|---|---|
| Primärer Zweck | Technische Zugriffskontrolle | Inhaltliche Orientierungshilfe |
| Zielgruppe | Web-Crawler (Googlebot etc.) | KI-Modelle & RAG-Systeme |
| Rechtliche Wirkung | Bindend für respektvolle Bots | Keine (informeller Vorschlag) |
| UrhG-Relevanz (§ 44b) | Maschinenlesbarer Vorbehalt | Unklar / Ergänzend |
| Format | Textbasiert (Standard) | Markdown (Strukturiert) |
Quelle der Spezifikation: llmstxt.org, Orientierungshilfe für LLMs
Sie haben nun die ersten Daten zur technischen Struktur Ihrer Seite vorliegen. Was jetzt fehlt, ist die Gewissheit, ob KI-Systeme wie ChatGPT oder Perplexity Ihre Inhalte korrekt erfassen und als Quelle zitieren können.
Welche 5 Pflicht-Sektionen eine llms.txt für Unternehmenstextgeneratoren und Wissensseiten enthalten sollte
Eine funktionierende llms.txt für Unternehmenstextgeneratoren braucht fünf Kernelemente: Unternehmenskontext, Produktstruktur, Zielgruppen-Definitionen, Tonalität und Fakten-Quellen. Damit verstehen KI-Systeme wie ChatGPT, Claude oder Perplexity, wer Du bist, und geben Deine Inhalte korrekt weiter, ohne Deine Marke zu verzerren.
Sektion eins: der Unternehmenskontext. Nicht als Marketingtext, sondern als Fakten. Gründungsjahr, Rechtsform, Standort, Kernleistungen. Ein Beispiel: „STEP/SEEDS GmbH, gegründet 2024, Berlin, spezialisiert auf Marketing-Diagnose für KMU in Deutschland, Österreich, Schweiz. Kernprodukt: 48h-Diagnose mit ROI-Priorisierung, ab 199 Euro.“ Ohne diese Klarheit verwechseln KI-Systeme Dich mit Wettbewerbern oder ordnen Deine Leistungen falsch ein. 34 % der deutschen KMU nutzen inzwischen KI-gestützte Recherche-Tools für Lieferantenauswahl [Quelle: Bitkom, 2025]. Deine llms.txt entscheidet, ob Du dabei korrekt dargestellt wirst, oder nicht.
Sektion zwei: die Produktstruktur. Welche Angebote, wie hängen sie zusammen, welche Preise. Konkrete SKUs, Pakete, Upgrade-Pfade. „Free Tools: AI-Check, Agentur-Check, BAFA-Check (kostenlos, Lead-Qualifizierung). Paid: Marketing-Diagnose (199–499 Euro, 48h-Lieferung). Enterprise: Custom Audit (ab 2.500 Euro).“ Damit positionieren sich Deine Angebote in KI-Vergleichsanfragen richtig, statt dass ChatGPT Deine Diagnose als „Beratungsstunde“ beschreibt oder erfundene Preise nennt.
Sektion drei: die Zielgruppen. Für wen schreibst Du, welche Branchen, welche Unternehmensgrößen, welche Rollen. „Primär: Geschäftsführer und Marketing-Verantwortliche in KMU 10–250 Mitarbeiter, Deutschland. Branchen: Dienstleistung, Handel, Handwerk, Kanzleien. Sekundär: Gründer, Freelancer, Agenturen.“ Diese Angabe steuert, in welchen Kontexten KI-Systeme Deine Inhalte empfehlen. Bietest Du B2B-Software für Steuerberater an und hast keine Zielgruppen-Definition, landet Dein Content in Antworten für Privatpersonen. Deine Conversion sinkt.
Sektion vier: die Tonalität. Sie-Form oder Du-Form, formell oder kollegial, technisch oder allgemeinverständlich. „Anrede: Sie-Form (warm B2B). Tonalität: strategisch-klar, keine Floskeln, keine Drama-Sprache. Zielgruppe: Unternehmer 35–60 Jahre, Mittelstand Deutschland.“ Damit paraphrasiert die KI Deine Texte im richtigen Ton. Wenn Deine Marke auf ruhige Kompetenz setzt, aber die KI Deine Inhalte mit „revolutionär“ und „game-changing“ zusammenfasst, verlierst Du Glaubwürdigkeit bei Deinen Kunden.
Sektion fünf: die Fakten-Quellen. Welche Studien, Statistiken, Benchmarks Du nutzt, welche Quellen verifiziert sind. „Primärquellen: Bitkom, Statista, BVDW, IHK, Google Developers. Datenstand: 2025–2026. Keine Affiliate-Blogs, keine unverifizierten LinkedIn-Posts.“ Damit verknüpfen KI-Systeme Deine Aussagen mit echten Quellen und markieren sie als „fact-checked“. Ohne diese Sektion riskierst Du, dass Deine Zahlen als „unbelegt“ eingestuft werden, oder dass KI-Systeme Deine Daten mit fragwürdigen Quellen mischen und Deine Autorität verwässern.
Wie Du eine llms.txt in 6 Schritten sauber aufsetzt, prüfst und veröffentlichst
Die Bereitstellung einer llms.txt ist ein strategischer Schritt, um die Sichtbarkeit Ihrer Unternehmensinhalte in KI-gestützten Suchsystemen zu sichern. Während herkömmliche Suchmaschinenoptimierung auf menschliche Leser und Algorithmen abzielt, bereitet dieses Format Ihre Daten gezielt für Large Language Models (LLMs) auf. So stellen Sie sicher, dass KI-Agenten die relevantesten Informationen Ihrer Website korrekt erfassen und priorisieren.
- Dateistruktur festlegen. Erstellen Sie eine einfache Textdatei mit dem Namen llms.txt. Diese muss zwingend im Root-Verzeichnis Ihrer Domain liegen (beispiel.de/llms.txt), damit Crawler sie zuverlässig finden.
- Strukturierte Markdown-Syntax nutzen. Verwenden Sie für die Formatierung Markdown. Beginnen Sie mit einer H1-Überschrift, die den Namen Ihrer Website oder Ihres Projekts enthält, gefolgt von einer kurzen, prägnanten Zusammenfassung des Kernangebots.
- Relevante Sektionen definieren. Unterteilen Sie die Datei in klare Abschnitte wie „Kerninhalte“ oder „Dokumentation“. Nutzen Sie H2-Überschriften, um den KI-Modellen eine logische Hierarchie Ihrer Informationsarchitektur zu bieten.
- Links und Beschreibungen einpflegen. Listen Sie die wichtigsten URLs Ihrer Website auf. Fügen Sie jeder URL eine kurze Beschreibung hinzu, die den Kontext erklärt. Dies hilft der KI zu verstehen, welche Seite spezifische Fragen beantwortet.
- Optionale llms-full.txt erstellen. Wenn Sie umfangreiche Dokumentationen oder tiefere Informationsebenen besitzen, verlinken Sie am Ende Ihrer llms.txt auf eine llms-full.txt. Diese dient als erweiterter Index für sehr detaillierte Datenbestände.
- Live-Prüfung und Validierung. Laden Sie die Datei auf Ihren Server hoch und prüfen Sie die Erreichbarkeit im Browser. Nutzen Sie Tools wie den „llms.txt Validator“, um sicherzustellen, dass die Syntax von gängigen KI-Crawlern korrekt interpretiert werden kann.
Sie haben nun die technische Basis geschaffen, damit KI-Systeme Ihre Inhalte effizienter verarbeiten können. Dennoch bleibt die Frage offen, welche Ihrer Inhalte für die KI-gestützte Suche tatsächlich den höchsten wirtschaftlichen Hebel besitzen. Eine Liste von Links ist ein Anfang, die strategische Auswahl der Daten, die Ihre Conversion-Rate beeinflussen, erfordert eine tiefere Analyse Ihrer digitalen Architektur.
Welche Fehler bei AI-Bot-Allowlist, Schema-Markup und Over-Blocking die Sichtbarkeit am stärksten bremsen
Technische Barrieren sind oft der Grund, warum Unternehmen trotz hochwertiger Inhalte in KI-Antworten von ChatGPT, Claude oder Perplexity nicht auftauchen. Wenn Crawler durch fehlerhafte Konfigurationen blockiert werden, bleibt Ihre Expertise für Large Language Models (LLMs) unsichtbar. Die folgende Tabelle zeigt Ihnen die kritischsten Fehlerquellen und deren wirtschaftliche Auswirkung auf Ihre digitale Sichtbarkeit.
| Fehlerquelle | Priorität | Auswirkung auf die KI-Sichtbarkeit |
|---|---|---|
| Restriktive robots.txt (User-Agent Blocking) | Kritisch | KI-Crawler werden komplett ausgesperrt; Inhalte können nicht für Antworten verarbeitet werden. |
| Fehlendes oder fehlerhaftes Schema-Markup | Hoch | LLMs interpretieren Daten falsch oder ignorieren unstrukturierte Informationen bei komplexen Anfragen. |
| Over-Blocking durch Firewalls/IP-Filter | Hoch | Legitime KI-Bots werden fälschlicherweise als Angriffe gewertet und auf Serverebene blockiert. |
| Fehlende llms.txt Datei | Mittel | Verlust einer ergänzenden Richtlinie zur besseren Inhaltsstrukturierung für KI-Modelle. |
Quelle: Google Search Central, Offizielle Dokumentation zur robots.txt-Konfiguration
Welche Compliance-Fragen der EU AI Act und TDM-Opt-out für llms.txt in Deutschland auslösen
Der EU AI Act zwingt Anbieter von General-Purpose-AI-Modellen (GPAI) nach Artikel 53 dazu, das Urheberrecht einzuhalten, konkret: Sie müssen offenlegen, womit Sie Ihre Modelle trainiert haben. Für deutsche Unternehmen heißt das: Wer KI-Text-Tools nutzt oder selbst Modelle trainiert, muss TDM-Opt-outs (Text and Data Mining) nach § 44b UrhG technisch umsetzen. Entweder über robots.txt oder das neue llms.txt-Format. Die Frage ist nicht ob, sondern wann Ihre AGB, Website-Struktur und Datenschutzerklärung mit diesen Vorgaben kollidieren.
Das BMWK-Leitfaden ist eindeutig: GPAI-Anbieter müssen nachweisen, dass sie urheberrechtlich geschützte Inhalte nicht ohne Erlaubnis trainieren. Die Realität sieht anders aus. Viele deutsche KMU haben in ihren AGB vage Formulierungen wie „Wir behalten uns vor, Inhalte zu analysieren“ – ohne zu klären, ob das auch KI-Training meint. Gleichzeitig erstellen sie eine llms.txt-Datei, die bestimmte Website-Bereiche für KI-Crawler sperrt. Das ist ein direkter Widerspruch. Ihre AGB erlauben möglicherweise mehr, als Ihre technische Konfiguration zulässt. Und dieser Widerspruch ist rechtlich angreifbar. Bei der ersten Abmahnung wird es teuer.
Hinzu kommt: Die Konsistenz zwischen TDM-Opt-out und Datenschutzerklärung. § 44b UrhG erlaubt Text and Data Mining für wissenschaftliche Zwecke, aber nur, wenn der Rechteinhaber nicht widersprochen hat. Wenn Sie in Ihrer Datenschutzerklärung schreiben „Wir verarbeiten Daten zu Analysezwecken“, aber in llms.txt KI-Crawling verbieten, entsteht eine Lücke: Warum dürft ihr selbst analysieren, aber Dritte nicht? Diese Erklärung fehlt auf den meisten KMU-Websites. Und genau da setzt die nächste Abmahnwelle an. Du brauchst keine neue Rechtsabteilung. Du brauchst eine klare Entscheidung: Entweder erlaubst Du TDM explizit und dokumentierst die Bedingungen. Oder Du verbietest es technisch und passt Deine AGB an. Beides gleichzeitig funktioniert nicht.
Welcher Grundsatz für KMU gilt: llms.txt ist Governance, nicht Garantie
llms.txt ist ein Angebot an KI-Modelle, kein Zwang, und schon gar keine Garantie, dass ChatGPT, Claude oder Perplexity Deine Inhalte korrekt zitieren. Die Datei funktioniert wie eine erweiterte robots.txt: Du markierst darin, welche Inhalte KI-Tools crawlen dürfen und wie sie diese interpretieren sollen. Aber ob die Modelle das tatsächlich befolgen? Das liegt außerhalb Deiner Kontrolle. SE Ranking hat das untersucht, Ergebnis: Es gibt bislang keine verlässlichen Belege dafür, dass llms.txt die Zitierwahrscheinlichkeit oder Dein Ranking in AI-Suchergebnissen messbar verbessert [Quelle: SE Ranking, 2025]. llms.txt ist ein Signal. Mehr nicht.
Für KMU heißt das konkret: llms.txt lohnt sich, wenn Du ohnehin strukturierte Inhalte pflegst und Deine Marke in KI-Antworten sichtbar sein soll. Du definierst darin, welche Seiten crawlbar sind, welche Kontaktdaten Du bevorzugst, welche Inhalte als zitierfähig gelten. Aber Du kannst nicht erzwingen, dass ein LLM Deine Quelle nennt, Deine Wortwahl übernimmt oder Deine Marke in der Antwort erwähnt. Das Modell entscheidet, und die Logik dahinter bleibt eine Black Box. llms.txt regelt Spielregeln, nicht Ergebnisse.
Was das praktisch bedeutet: Nutze llms.txt, wenn Du bereits strukturierte Daten (Schema.org), saubere Metadaten und klare Quellenangaben pflegst. Aber plane nicht mit messbaren Effekten in den ersten 6–12 Monaten. KI-Sichtbarkeit entsteht nicht durch eine Datei. Sie entsteht durch Autorität, klare Positionierung und Inhalte, die LLMs selbst als zitierwürdig einstufen, mit oder ohne llms.txt.
Praktisches Fazit
llms.txt ist kein Ersatz für strukturierte SEO-Arbeit, es ist eine Ergänzung für Unternehmen, die bereits technisch sauber aufgestellt sind und gezielt AI-Sichtbarkeit aufbauen wollen. Für die meisten deutschen KMU gilt 2026: Erst die Basis sichern (strukturierte Daten, mobile Performance, klare Informationsarchitektur), dann AI-Optimierung als zusätzlichen Kanal erschließen. Wer llms.txt ohne funktionierende Schema.org-Auszeichnung oder mit einer Ladezeit über 3 Sekunden einsetzt, investiert in die falsche Reihenfolge.
Die wirtschaftliche Logik ist brutal einfach: Strukturierte Daten wirken auf Google Search und auf AI-Systeme gleichzeitig – 92% des deutschen Suchvolumens laufen über Google [Quelle: Statista 2025]. llms.txt? Nur AI-Systeme. Und die decken derzeit 8–12% der Recherche-Anfragen deutscher Nutzer ab [Quelle: Bitkom Digital Office Index 2025]. Wer zuerst llms.txt pflegt, optimiert für den kleineren Kanal. Der größere bleibt liegen. Das ist kein strategisches Denken, das ist Reihenfolge-Fehler mit messbarem Umsatz-Risiko.
Für Unternehmen mit professioneller technischer Basis, Core Web Vitals grün, Schema.org vollständig implementiert, mobile-first Design, ist llms.txt 2026 tatsächlich sinnvoll. Du kannst damit gezielt steuern, welche Inhalte Large Language Model Textgenerator-Systeme wie ChatGPT Search oder Claude bevorzugt indexieren. Besonders wertvoll: FAQ-Seiten, Produktdokumentationen, Branchenwissen, das sich für intelligente Textgenerierung eignet. Der Aufwand? 30–60 Minuten pro Quartal. Der Ertrag: messbare Sichtbarkeit in AI-gestützten Recherche-Workflows, wenn die technische Grundlage stimmt.
Die Priorisierung für 2026 lautet konkret: Technische Performance und strukturierte Daten zuerst (Wirkung auf 90%+ der Nutzer). Dann Content-Qualität und interne Verlinkung (Wirkung auf Conversion und Verweildauer). Dann AI-Optimierung als dritter Schritt (Wirkung auf wachsenden, aber noch kleinen Kanal). Wer diese Reihenfolge umdreht, baut auf instabilem Fundament, und verliert Umsatz an Wettbewerber, die strukturiert vorgehen.
STEP/SEEDS® Marketing-Diagnose
Sie haben die ersten Daten und verstehen die Richtung. Was jetzt fehlt, ist die Priorisierung in Ihrem konkreten Kontext, welche Hebel zuerst, welche Investitionen sich messbar lohnen und welche Reihenfolge Geld spart. Eine professionelle Diagnose findet typischerweise 3–5 Hebel mit messbarem Umsatzeffekt und zeigt Ihnen die exakte Umsetzungsschritte.